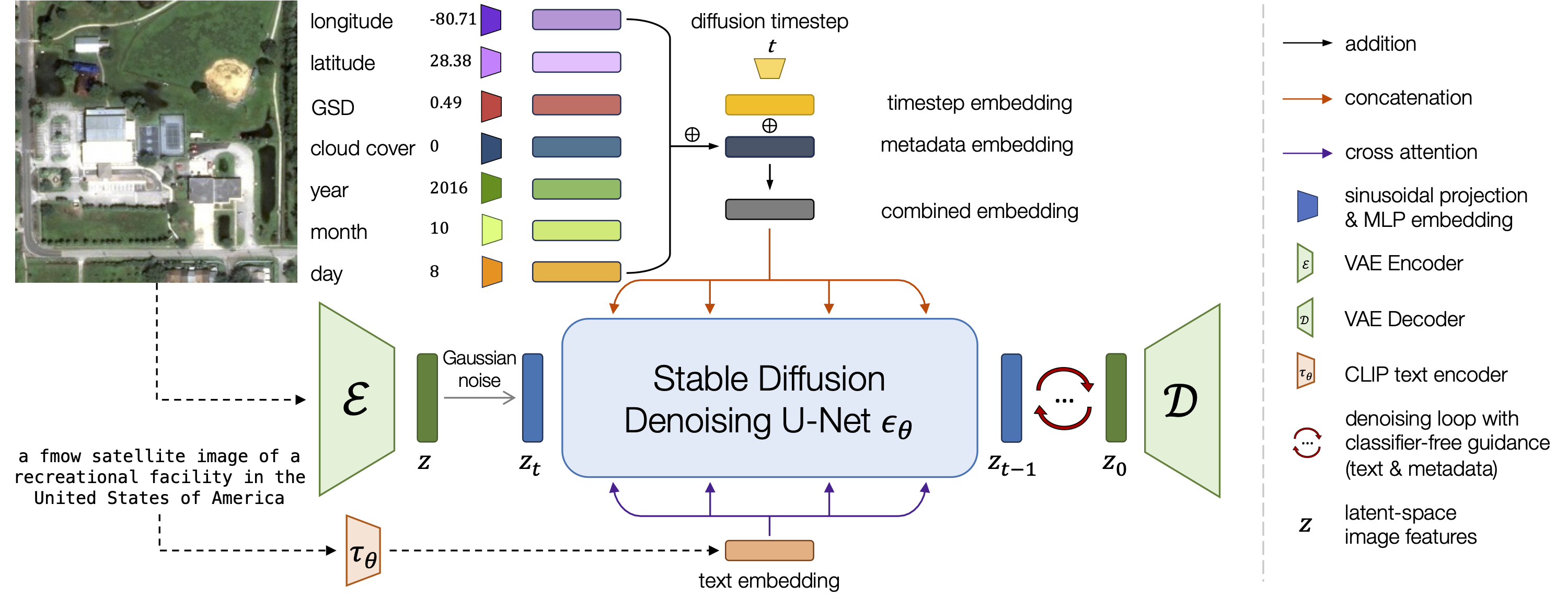
Diffusion models have achieved state-of-the-art results on many modalities including images, speech, and video. However, existing models are not tailored to support remote sensing data, which is widely used in important applications including environmental monitoring and crop-yield prediction. Satellite images are significantly different from natural images -- they can be multi-spectral, irregularly sampled across time -- and existing diffusion models trained on images from the Web do not support them. Furthermore, remote sensing data is inherently spatio-temporal, requiring conditional generation tasks not supported by traditional methods based on captions or images. In this paper, we present DiffusionSat, to date the largest generative foundation model trained on a collection of publicly available large, high-resolution remote sensing datasets. As text-based captions are sparsely available for satellite images, we incorporate the associated metadata such as geolocation as conditioning information. Our method produces realistic samples and can be used to solve multiple generative tasks including temporal generation, superresolution given multi-spectral inputs and in-painting. Our method outperforms previous state-of-the-art methods for satellite image generation and is the first large-scale generative foundation model for satellite imagery.
First, we discuss how DiffusionSat generates standalone (single) images. We initialize a denoising UNet with StableDiffusion 2.1 weights and pretrain the model on a collection of large, publicly available satellite datasets such as fMoW, SpaceNet and Satlas. We generate rough captions from available class and bounding box information. Simply using these captions isn't enough-- we find that the key to good satellite image generation is to condition on numerical metadata in the same way as the diffusion timestep (with a sinusoidal projection and MLP embedding). Doing so leads to more controllable generation, seen below.

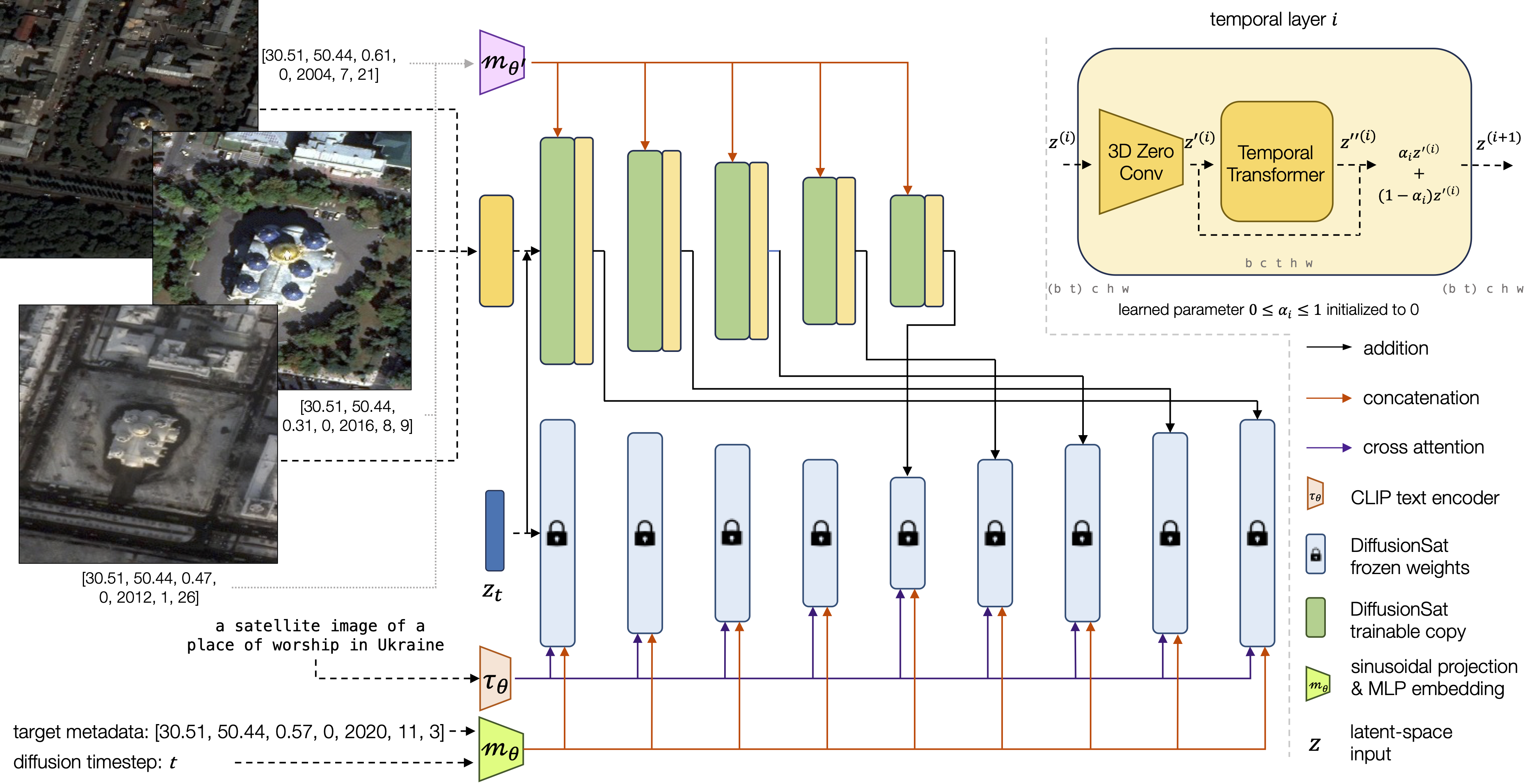
In addition to single image generation, we demonstrate DiffusionSat's ability to solve a range of inverse
problems, such as superresolution, temporal prediction/interpolation, and in-painting. Broadly, solving these problems
requires conditioning on a control signal, which can be another image, spectral bands, or a sequence of images.
To tackle this class of problems, we modify a ContolNet architecture to accept sequences of image input. Each item
in the sequence is associated with its own metadata. This architecture then enables DiffusionSat to condition on
an input control signal (eg: a low-resolution image) and then generate a new image corresponding to target metadata
(eg: a superresolved high-resolution image).
Arguably, the most widely recognized generative inverse problem for remote sensing data is superresolution. We show that given a multi-spectral, low-resolution (10m-60m GSD) Sentinel-2 image, DiffusionSat can reconstruct the corresponding high-resolution (~0.3m GSD) fMoW image. This is an especially challenging task, since the input must be upsampled >20x. We train the super-resolution model using a dataset of paired (fMoW-Sentinel, fMoW-RGB) images.

SWIR, NIR, and RGB refer to the different multispectral bands of Sentinel-2 images. HR corresponds to the
ground-truth high-resolution image. SD refers to vanilla StableDiffusion. DiffusionSat does well to reconstruct
realistic high-resolution images compared to other baselines. However, like other diffusion models, it can sometimes
hallucinate small details in the images to preserve realism over an exact reconstruction.
Read the paper for more details on another super-resolution task using the Texas Housing dataset!
With DiffusionSat's ability to condition on input sequences, we can tackle inverse problems such as temporal prediction and interpolation. Given a sequence of input satellite images of a location distributed across time (not necessarily in order), along with their corresponding metadata, we can prompt DiffusionSat to reconstruct an image in the past, in the future, or anywhere in the middle of the temporal sequence. We use the fMoW-RGB dataset and construct temporal sequences of images of the same location. DiffusionSat is then trained to reconstruct a randomly chosen target image given the other images (in any order) of the sequence.

The ground truth images are in the center, marked by their years and months. The column of images with the date marked under the blue date represent the target image in the past to reconstruct, given the other three images (to the right) as input. The reconstructions from different models are shown to the left. Similarly, the column of images marked under the red date are the target future images to reconstruct given the three images to the left as input. DiffusionSat is able to predict images in the past and future effectively, once again proving capable to tackle challenging inverse problems.
Inpainting is another inverse problem where the goal is to reconstruct portions of the image which have been corrupted. Rather than artificially corrupt input images, we choose the xBD dataset which contains before and after images of locations afflicted by different natural disasters. The goal is to reconstruct the before-disaster image given the post-disaster image, or vice versa. In-painting consists of reconstructing damaged roads, houses, and landscapes given the post-disaster image, or adding damage to regular images.

The caption on the left of each row of 4 images is the disaster type. The "pred-past" column represents DiffusionSat's reconstruction given the after-disaster image (marked by the date in red) as input. Similarly for the "pred-future" column, given the before-disaster image as input. DiffusionSat effectively reconstructs houses and roads which have been partially or almost completely damaged in floods, fires and other disasters. It can even reconstruct parts of the image masked by cloud cover. We hope this can play a role in assisting teams to respond effectively to natural disasters.
We can combine the single-image and conditional DiffusionSat architectures to auto-regressively generate full sequences of satellite images! We do this by generating the "seed" image from single image DiffusionSat (given an input text prompt and metadata), and then using conditional DiffusionSat to predict the next image for some desired metadata. Then, both images form the control signal input for the next generation, and so on.

Like other diffusion models, DiffusionSat can occasionally hallucinate details, and its results can vary significantly for a given prompt or control signal. Users should be mindful of these limitations when assessing the outputs of models like DiffusionSat. Further research on controlling the reliability of diffusion model outputs will be crucial to make accurate geospatial predictions for inverse problems such as super-resolution and temporal prediction. More research on producing large-scale caption-annotated satellite image datasets will also be very helpful!
@inproceedings{
khanna2024diffusionsat,
title={DiffusionSat: A Generative Foundation Model for Satellite Imagery},
author={Samar Khanna and Patrick Liu and Linqi Zhou and Chenlin Meng and Robin Rombach and Marshall Burke and David B. Lobell and Stefano Ermon},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=I5webNFDgQ}
}